一、阿里云大数据计算服务概述
阿里巴巴大数据计算服务MaxCompute的前身叫做ODPS,是阿里巴巴内部统一的大数据平台,其实从ODPS到MaxCompute的转变就是整个阿里巴巴大数据平台的演化过程。所以在本次会着重分享阿里巴巴大数据在过去七八年的时间所走过的路以及后续技术发展大方向。

首先做一个基本的定位,大家可以看到下面这张图是一个航空母舰战队。如果把阿里巴巴整体数据体系比作这个战队,那么MaxCompute就是中间的那艘航空母舰,几乎阿里巴巴99%的数据存储以及95%的计算能力都在这个平台上产生。

每天有大概超过一万四千名阿里巴巴内部的开发者会在这个平台上进行开发,也就是每四个阿里员工中就有一个在使用这个平台。每天有超过三百万个作业在这个平台上运行,几乎涵盖了阿里内部所有的数据体系,包括支付宝的芝麻信用分,淘宝商家的每日商铺账单以及“双11”的大流量处理都是在这个平台上进行的。
MaxCompute平台有上万台服务器分布在多个不同地域的集群中,具备多集群的容灾能力。在公共云上,MaxCompute每年以250%的用户量和计算量在增长。此外MaxCompute对接到专有云平台上提供了几十套的部署,这里包括了大安全、水利等所有政府业务,也包括城市大脑项目,几乎所有城市大脑项目的底层都是使用这套系统做存储和大数据计算服务,以上就是对于MaxCompute平台的整体定位。
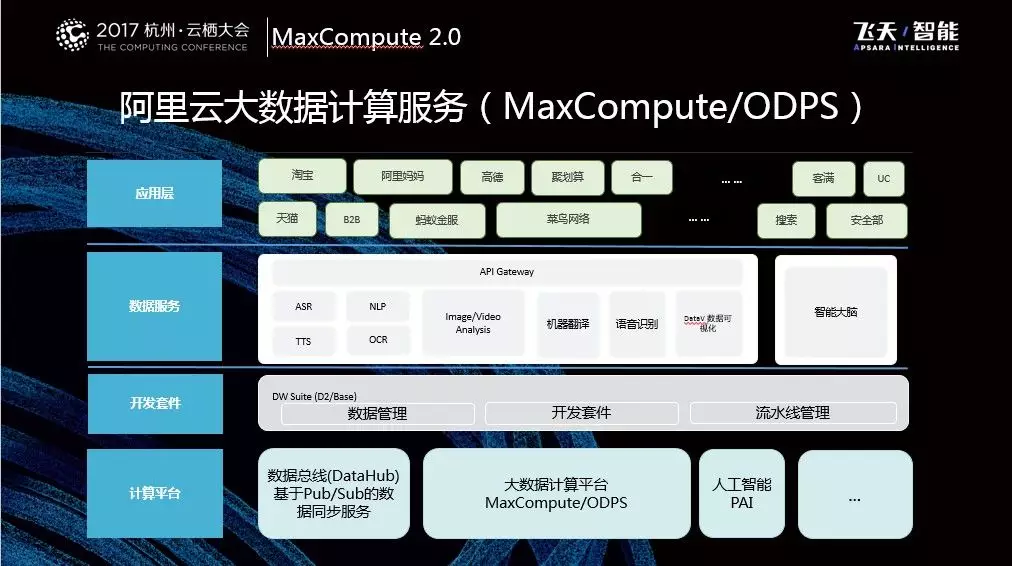
如下图所示的是MaxCompute平台技术全景图。其中最底层是计算平台,最下面是数据流入流出的数据总线,称为DataHub,它现在也为公有云提供服务。数据会通过DataHub流入到MaxCompute大数据计算平台上来,在MaxCompute平台上会与包括人工智能平台在内的所有平台进行互动构成完整数据平台的计算体系。
在这之上是开发套件,如Dataworks、MaxCompute Studio,其包括最基本的对数据的管理和认知、对于数据的开发以及对作业的开发和管理。针对于这样的开发和基础平台,向上提供的计算服务包括语音转文本、光学文字识别、机器翻译以及智能大脑这些业务类的产品。在应用层就包括了向淘宝、天猫等比较老牌的淘系产品以及比较新的高德、菜鸟网络以及合一集团等提供所有的技术服务,以上就是MaxCompute平台对内和对外的整体布局。
二、阿里巴巴数据平台进化之路
接下来分享MaxCompute平台在过去的七八年时间里是如何演化的。在淘系建立之初,在2009年之前使用基本都是IOE的系统,当时阿里更加偏重电商系的系统,属于垂直线的。当时每个BU都有自己的一套从上到下、从业务到平台的产品。2009年的时候,使用的数据库基本都是Oracle,当时阿里巴巴拥有亚洲最大的Oracle集群,所以在那个时候戏称为Oracle之巅,当时的计算规模已经到达百TB的级别了。
然后发现随着淘宝运算量的发展,也随着用户量每年以百分之几百甚至上千的增长速率不断增加,Oracle集群无法承接所有业务的发展,所以当时思考的第二个项目就是Greemplum。因为Greenplum与Oracle的兼容度比较好,所以当时想到在Oracle遇到瓶颈的时候使用Greenplum做第二条的基础发展路线。

在阿里巴巴发展之初,各BU都以各自为战的状态发展,其实这也是各个公司在创立之初的普遍状态。大约经过了一年多的时间,阿里巴巴又遇到了Greenplum的天花板,此时的数据量大概比Oracle扩展了10倍。但是此时发现Greenplum在百台机器之后就很难再扩展上去了,但是即便是百台机器的规模对于阿里这样蓬勃发展的企业而言是远远不够的。
2009年9月阿里云启动,当时给出的愿景是要做一整套计算平台,其包括三大部分:底层的分布式存储系统——盘古、分布式调度系统——伏羲、分布式大数据存储服务——ODPS,也就是现在的MaxCompute。
大概花了一年的时间,第一个平台开始运行了,当时的ODPS就作为核心的计算引擎在其中发挥作用。
到了2012年,这个平台基本上稳定了,这时候开始做到数据统一存储、数据统一的标准化和安全统一管理。当做实现了上述目标之后,在2013年的时候开始大规模的商业化。当时做了一个“5K”项目,也就是单集群突破5千台,同时具备多集群的能力,这种二级扩展能力基本上就标志着阿里内部的数据平台的奠基基本完成。
与此同时,因为在做这套产品时候,由于各个BU之间之前是各自为战的,有很多的BU采用了开源的Hadoop体系,所以在当时有两套体系同时存在,一套称为云梯1也就是基于开源体系的,另外一套叫做云梯2就是阿里内部自研体系的。那时候阿里巴巴的Hadoop集群做到了亚洲最大规模,达到了5000台,能够提供PB级别的数据处理能力。
2014年到2015年,因为有两套技术体系并立,所以阿里内部做了一个决定就是将整个技术体系进行统一,所以启动了“登月”计划。而在“登月”的过程中必须要考虑几个需求:
- 多集群的能力
- 良好的安全性
- 海量的数据处理能力并且需要具备金融级的稳定性。
基于上述需求,阿里巴巴当时选择了云梯2系统,也就是今天大家看到的MaxCompute。
2016年到2017年,MaxCompute开始对内支撑所有的业务,并且也开始对外提供服务。多集群扩展到超过万台,并且开始全球化的部署,现在MaxCompute在美东、美西、新加坡、日本、澳大利亚、香港、德国以及俄罗斯都部署了集群。

登月计划 —— 一个统一的过程
接下来分享“登月”计划和为什么选择这样的一条技术路线。正如上述所提到的在执行“登月”计划之前,各个BU之间存在着大大小小数十个计算平台,这是业务初期的必然属性。而在技术上最终出现了两套体系,一套是基于开源的体系,另外一套则是基于自研的体系。其实这两套体系在技术和架构上来讲或多或少都有相互的借鉴,但是在技术发展线路上又各不相同,在数据存储格式、调度方法以及对外运算接口上也是各不相同的。当时遇到了以下几个问题:
- 扩展性差,在两三年前的那个时候,Hadoop体系的NameNode,JobTracker,HiveServer等都还是单点系统,在稳定性层面上存在一定的问题。
- 性能低,在5K及以上的规模上引擎性能的提升有限,也就是在5K以下基本上可以做到线性扩展,但是超过5千台之后可能就会有问题。
- 安全性不够高,这一点是非常值得关注的问题。因为整个阿里巴巴在万人级别的规模上是一套标准的多租户体系。所谓多租户就是阿里有很多个BU,每个BU之下有很多个部门,每个部门之下还有组和员工,那么每个BU以及每个部门之间获取的权限应该是不同的,对于如何在数据安全的前提下进行共享的要求非常高,对此基于文件的授权体系不能满足灵活要求。
- 稳定性比较差,不能支持多个集群和跨集群容灾。
并且当时代码虽然开源但反馈回社区的周期很长,很多集群变成事实上的“自研”系统;这又进一步导致的版本不统一,各个集群无法互联互通!当时出现的问题就是淘宝的数据,天猫都无法使用,小微金融的数据其他的BU也无法使用,互相申请权限非常困难,整个体系无法打通。但是大家都知道阿里巴巴不是依靠实体资产,阿里巴巴没有商品和仓储,内部最为核心的就是数据资产。如果在平台性的体系中,数据无法做到互联互通和高效运转,那么就会对公司发展造成很大的危害。
所以阿里巴巴就经历了这样的一个“漫长”和“昂贵”的登月过程。在登月计划中,阿里巴巴集团层面牵头,其中有名有姓的项目大概有24个,当时的登月1号是阿里金融,登月2号是淘宝,这24个项目的“登月”总共历时了一年半的时间,将整个数据统一到了一起。

为了保障“登月计划”的顺利实施,当时MaxCompute平台做了这样的几件事情:
- 保证能够满足当时Hadoop集群所能够提供的功能,在性能方面至少不会比其他平台差。
- 在编程接口层面,需要让编程模型等多个方面兼容。
- 提供完善的上云工具和数据迁移/对比工具,使得可以方便地从Hadoop体系中迁移到MaxCompute上来。
- 由于不得不在业务进行中升级,和业务方一起做无缝升级方案,“在行驶的飞机上换引擎”。

在实现了统一之后大致有这样三点好处:
- 打造了集团统一的大数据平台。“登月计划”将阿里巴巴内部所有的机器资源、数据资源统一到了一起。因为数据具备“1+1>2”的特性,所有的数据贯通之后,集群整体的利用效率、员工的工作效率以及数据流转等方面就变得非常高效的。到目前阿里集团内部计算业务运行于MaxCompute集群上,总存储能力达到EB级别,每天运行ODPS_TASK超过几百万。
- 新平台是安全的,同时可管理、能开放。因为阿里巴巴内部存储的数据和其他的厂商并不一样,阿里巴巴内部很多数据都是交易或者金融数据,所以对于数据的安全性要求非常高,比如同一张表中不同的字段对于不同的用户而言权限应该是不同的,MaxCompute平台提供了这种细粒度的安全性。在登月的过程中,不仅将数据统一到了一起,还实现了数据分级打标、数据脱敏、ODPS授权流程、虚拟域接入在云端查询版等工作。
- 新平台具备高性能和全面的数据统一。随着把数据统一到一起,阿里巴巴在管理平台上也做了统一化,比如统一的调度中心、同步工具和数据地图等,通过这些将阿里的数据体系进行全面的统一。而且新平台因为经过了很多的业务锤炼和梳理以及人员的整合,整个团队在一个比较大的规模上可以投入到一个平台上做更好的性能优化和功能调优,所以在2014年存储资源优化节约几百PB,通过梳理,各业务团队的作业数/计算量分别有30%-50%的下降,一些历史遗留问题得到全面的清理。
三、MaxCompute 2.0 Now and moving forward
接下来分享当阿里巴巴具备了内部统一的大数据平台之后,未来在基础和业务上应该如何做。
MaxCompute 2.0 架构持续升级
在2016年杭州云栖大会上,阿里巴巴发布了MaxCompute 2.0,那个时候推出了全新的SQL引擎并且提供非结构化处理能力,在2017年MaxCompute做了持续的创新和优化。
如下图所示,MaxCompute 2.0实现了很多的技术创新,最上面MaxCompute提供了DataWorks开发套件以及MaxCompute Studio;在运算模式上可以支持多种,比如批处理、交互式、内存以及迭代等。再往下在接口层面,今年会推出一个新的查询语言叫做NewSQL,它是阿里巴巴定义的一套新的大数据语言,这套语言兼容传统SQL特性,同时又提供imperative与declarative优势。

在引擎层面,优化器除了可以基于代价还可以基于历史运行信息进行优化。在运行时方面,将IO做成了全异步化。在元数据管理、资源调度和任务调度方面主要做了两件事,一个是做到了Bubble Based Scheduling,也就是当将所有作业数据连接到一起进行Bubble Shuffle的时候,要求上下游是完全拉起的,这对于资源的消耗是非常高的,而Bubble是通过做一个合理的failover 的Group在资源和效率上找到一个平衡点;另外一点是今年着眼于生态和开放性,可以和Hadoop以及Spark等集群做灵活的互动,这是今年在生态层面的发力。
在底层,MaxCompute今年除了提供原始的文件格式之外还提供了Index的支持,提供了AliORC,它与社区原生ORC兼容,性能却更高。此外,MaxCompute今年还开始做分级存储,除了内存和缓存以外,还会在SSD、SSD的HDD以及冷备压缩存储上做分层存储,今年其实在内部已经提供了超密存储的机型,未来也会逐步地转移到公有云上来。
大数据计算 典型场景分析(从开发到上线)
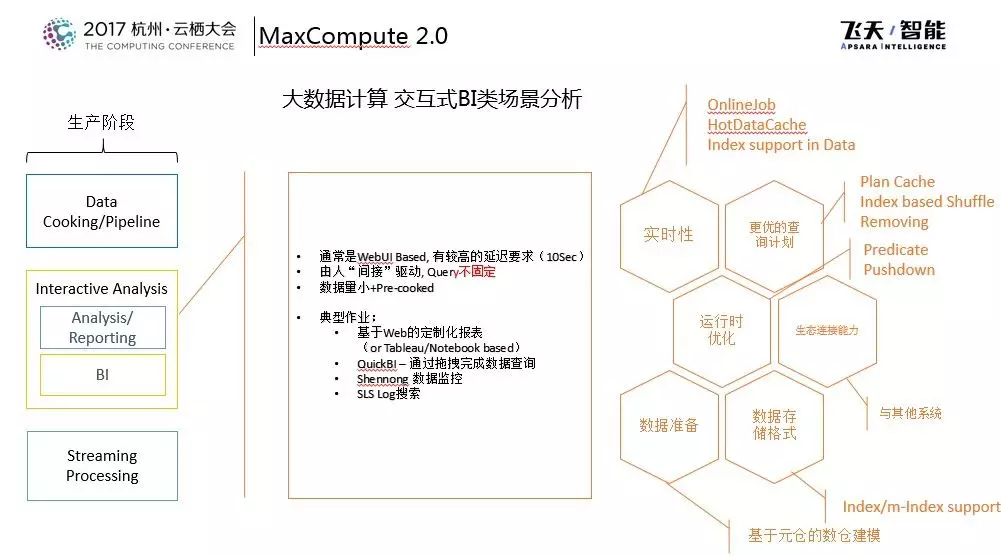
下图所示的是大数据计算的典型场景分析,这也是阿里内部大多数员工以及云上的经常会接触的事情。通常情况下,一套大数据体系的建立需要分成这样几个过程,需要从数据源到开发阶段再到生产阶段。
首先,数据源可以是应用,也可以是应用的服务,也可能来自应用的log日志。一方面可以将应用的信息通过log或者message的方式上传上来,另一方面很多数据信息其实落在DB中,DB的binlog其实可以被采集下来同步到数据平台中。
另外一部分数据源就是已有的存量数据。当拥有了这些数据之后可以通过主动拉取、手动上传以及同步中心的方式将数据上传到集群中来。之后就可以进入开发阶段,开发阶段又分为三个部分,第一个部分是数据发现,也就是究竟有什么样的数据可以用,通过IDE的方式做作业的编写或者做数据的编写。在开发阶段提供了通用计算、机器学习、图计算以及流计算等。

在开发完成之后进入到生产阶段,在生产阶段的Workload就分成3部分、一类叫做Workflow,每个月生成一份账单报表就是一个典型的Workflow任务,其特点就是具备周期性,比如每天、每小时或者每个月,这种类型的作业通常情况下作业量比较大,但是周期性却是可以预测的。
再往下就是Interactive Analysis,也就是交互式查询,大家可能某一天希望看到数据上的某些统计信息,然后基于这些信息做商业决策,这也许会写到明天的某一份报告里,这种是与开发者做交互的,写一个作业上去发现数据有问题再调整回来,然后来回做这样的交互。
第三点是基于时序或者流式的数据处理,这种处理比较典型的就是“双11”数据大屏,它就是滚动的流式计算的典型特点,基本的生产场景就分为以上三大类。
这三大类场景的要求是各不相同的,在数据源层面,对于数据的上传,当数据量比较大的时候,隔离流控是一个技术要点。同时当进入到生产阶段,数据的上传上载需要具备完整性的检查,包括需要进行规则检查的补充。当数据上传变成常规形态的时候,每天都会进行数据上传的时候就有可能因为系统、应用或者数据源的问题导致数据断裂,这种情况发生之后就需要系统具备补数据的能力。
而系统也需要对于开发阶段提供必要的支持,因为开发阶段通常是小数据量的,代码和脚本的更新速度比较快,可能经常处于试错的过程,所以需要系统具备准实时的能力、开发效率和Debug效率,这实际上是对人提出的要求。当进入到生产阶段的时候,通常情况下作业相对比较固定,资源和数据量消耗大,对于稳定性的要求就比较高,系统需要提供系统级别的优化能力以及运算能力。以上就是站在阿里巴巴的角度看的从开发到上线的大数据典型场景的分析。
大数据计算 典型场景分析(从计算量和延迟的角度)
下图所示的是一个从计算量和延迟的角度看的数据轴,从数据量上看,从100GB到10TB再往上,最高可以到PB级别,在“双11”当天,MaxCompute平台处理了上百PB的数据。在延迟的角度,会达到非常低的延迟状态。可以看到图中的橘色斜线,其含义是当对于数据量以及实时性的要求越高成本就会越高,所以大数据计算的要求就是将这个轴一直向上移动,也就是能够在更短的时间内处理更大量的数据的时候成本越来越低。

在作业分析来看,主要分成三块,其中最典型的数据清洗、数仓建立以及报表类的作业等通常情况下是以小时和天为单位运行的,按照阿里巴巴的数据统计基本上20%这样类型的任务会消耗掉80%的计算资源,这样任务的特定就是基本上以定时任务为主,query是固定的,所以通常情况下运行效率比较高。而实时监控类型的作业就是典型的流计算业务,比如像监控报警、大屏广播等。
而交互式作业大致分成两部分,一类是分析类的另外一类是BI类,BI类的意思是说大多数的人可能看不到Query和中间系统,只能看到BI环境比如像阿里云对外推出的QuickBI,大家可以通过配置和拖拽的形式访问系统,这种用户通常是非技术人员,这对于系统的交互性要求比较高,因为其是在UI上进行工作的,同时对于这样的工作一般有比较强的延时要求,一般是在秒级或者几十秒之内完成这样的作业,所以通常情况下数据量比较小,要求数据提前整理好。
交互分析的数据量处于中小级别,有一定的延迟要求。所以这样不同任务对应的不同的技术优化方案,Data Workflow就偏向pipeline型的作业,提升运行性能和效率是关键,对于以开发类和BI类的作业为主的,作业量比较大占大头,但是整体资源占用率比较低,对于这种类型开发效率和时序化是关键。今年在MaxCompute大数据平台的发展上,除了继续提升整体系统效率以外,时序化和开发效率也是今年的重点。
大数据计算 交互式BI类场景分析
在这三种Workload中重点分享一下其中比较基本的BI类的作业。为了实现这样的业务所以对于实时性有更高的要求,比如onlineJob的优化、热表Cache、Index Support等,还要有更优的查询计划、运行时的优化、生态连接、存储格式的进一步提升,需要在数据上支持Index使得在进行运算的时候可以将数据聚集到更小的规模上去,以上这些都是相关的优化。
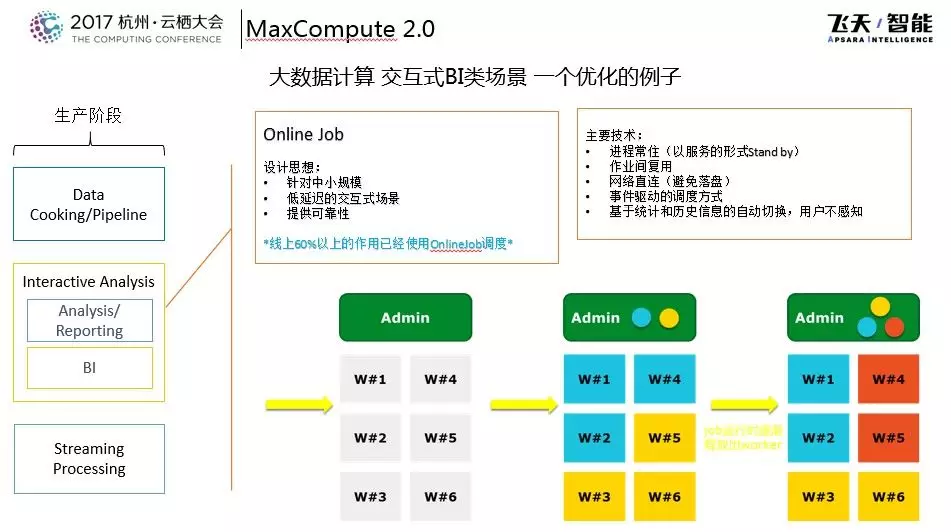
如下图所示的是OnlineJob的基本设计思想,OnlineJob主要是针对中等规模、低延迟的交互式场景,并且提供了可靠的服务,目前在阿里巴巴内部60%的作业都以这种方式来运行。这个模式主要使用了这样的几点技术:
- 进程常住(以服务的形式Stand by),进程随着作业完成之后不销毁,一直处于等待状态。
- 进程可以做到作业间复用。
- 网络直连,避免落盘。
- 事件驱动的调度方式。
- 基于统计和历史信息的自动切换,用户不感知。
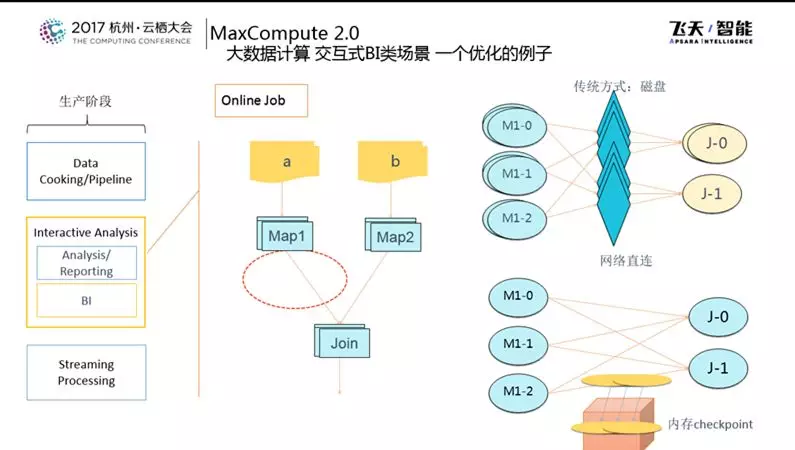
下图所展示的是交互式BI类场景下一个优化的例子。传统基于MapReduce的方式拉起多个Mapper做Shuffle的时候数据会落到磁盘里,然后再由下面的Join去读取,中间是割裂的,需要进行一次磁盘的数据交换,而MaxCompute的方式是做网络直连,这样的好处是不用等到第一个Session做完,第二个Session就可以启动,而这样同时也会带来一个坏处就是当failover的时候Group就会变得很大。
所以需要做的额外工作就是在内存中及时地进行Checkpoint,这个Checkpoint也可以做到SSD上或者另外一台机器上,这样的方式既提高了效率也降低了延迟并且能够保证failover Group不失效。
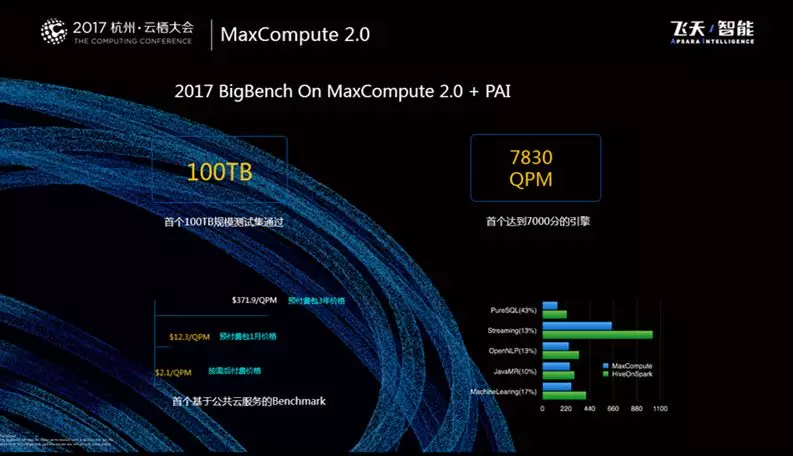
MaxCompute今年与Intel进行了合作在2017 BigBench新的大数据标准上做了评测,这个评测不再是简单地进行Sort,它一共具有30多个Query,这里面包括了基本的SQL Query以及MapReduce Query以及机器学习的作业,其评测的标准除了规模以外也会关心性价比。
目前MaxCompute是全球第一个将这些Query从10TB做到100TB级别的引擎,这样的能力也是基于阿里内部庞大的数据量的锤炼获得的,其次MaxCompute是首个达到7000分的引擎,第三点是MaxCompute性价比的优势,我们是首个基于公共云的服务可以跑通整个Query的服务,总体而言费用也是非常便宜的。
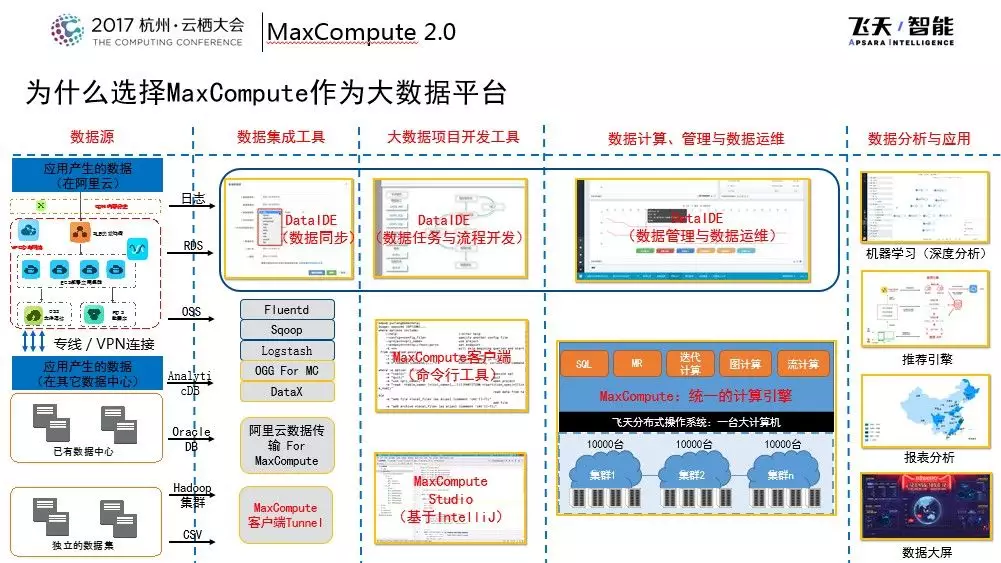
为什么选择MaxCompute作为大数据平台
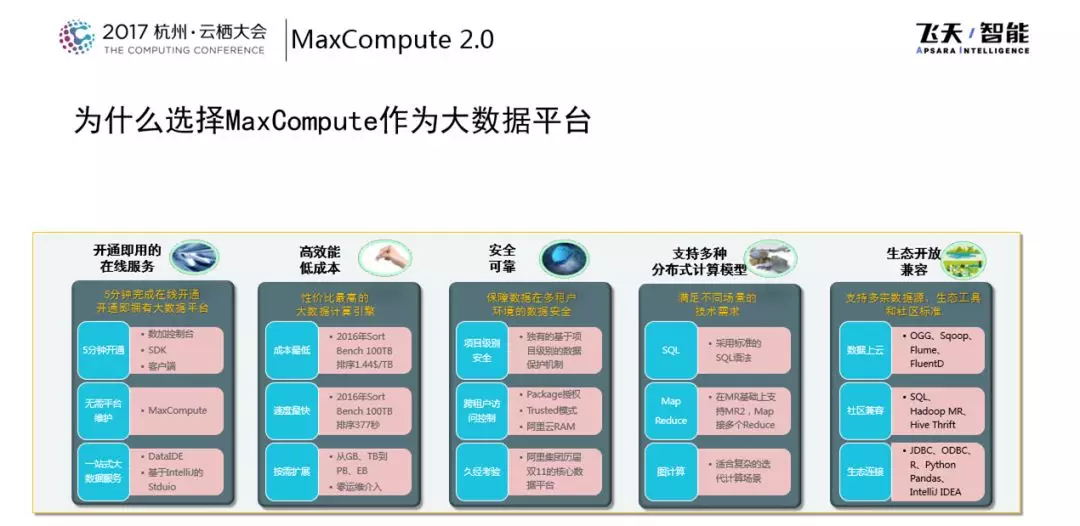
为什么选择MaxCompute作为大数据计算平台呢?在商业层面来讲,有以下几点优点:
- MaxCompute是一个开箱即用的系统,大家完全不用考虑系统的规模问题。
- MaxCompute有很多性能层面的评测和优化,可以实现性能和性价比的最优。
- MaxCompute基于阿里巴巴内部的非常丰富的安全体系保障多租户情况下的数据安全。
- MaxCompute可以支持多种分布式计算模型。
- MaxCompute支持上云工具,包括社区兼容和生态链。
从整体流程来看,如果用户的数据已经在阿里云上了,那么就可以非常容易地通过多种形式迁移到MaxCompute上来。如果数据在线下,可以通过专线或者VPN等形式在已有的数据集上通过各种同步工具迁移到云上。
在云上可以通过数据集成和大数据项目的开发工具进行开发。针对普通的数据集成可以使用Data IDE以及专门的插件进行开发。当进入集群中使用平台做数据计算服务的时候,可以非常方便地实现与机器学习平台的联动,也可以和阿里云的推荐引擎、报表分析产品工具等紧密地结合在一起。
我的分享就到这儿,谢谢大家。